An Ode to Header Files
C and C++ have a somewhat distinctive feature that almost no language since has decided to replicate, which is to put public API declarations into separate files called header files:
// square.h: defines public API
void SquareArray(int* p, size_t n);
// square.c: defines implementation
// Internal-only helper.
static int SquareNumber(int x) { return x * x; }
// Implementation of public API.
void SquareArray(int* p, size_t n) {
for (size_t i = 0; i < n; i++) {
p[i] = SquareNumber(p[i]);
}
}
More “modern” languages almost universally choose to collapse header and source into a single file, where public functions are marked in some special way:
// Rust: functions are exported with "pub"
fn square_number(x: i32) -> i32 { x * x }
pub fn square_array(arr: &mut [i32]) {
for i in arr.iter_mut() {
*i = square_number(*i);
}
}
// Java: functions are exported with "public"
class Square {
static int squareNumber(int x) { return x * x; }
public static void squareArray(int[] arr) {
for (int i = 0; i < arr.length; i++) {
arr[i] = squareNumber(arr[i]);
}
}
}
I think this move away from header files is unfortunate. Separating public API declarations into their own files offers many benefits that cut to the heart of good software engineering practice. In this blog post I will articulate what these benefits are. My hope is that modern languages might consider adopting something like header files (a few do to some extent, which I will explain later).
An Obsolete Mechanism, Repurposed
You may find it strange that I would advocate for header files, given that they are effectively obsolete, at least compared to their original purpose. Header files were initially designed to solve a technical problem for the compiler, which is how to share macros and function declarations between translation units in a way that supports separate compilation.
But newer languages have convincingly demonstrated that separate compilation
can be achieved without header files, and especially without the primitive and
problematic paradigm of textual inclusion (via #include), which is not
hygienic, meaning it can lead to namespace collisions, unbalanced scopes, and
numerous other practical problems.
So why do I advocate for an obsolete language feature? Because I believe that putting a module’s public API into a separate file is a genuinely good practice on the merits. Even if the machine no longer needs us to do it, it is good for humans.
I’m arguing for an updated, “modern” version of header files. This implies two clear breaks with C and C++:
- We should obviously not use textual inclusion, but instead make headers hygienic and modular, a la C++20 modules.
- We should allow headers to contain precisely the parts of a module’s API that are public, no more and no less. They should contain no implementation details whatsoever
C and C++ both traditionally violate (1), but C++ has tackled this problem head-on with C++20 modules, which should theoretically solve the problem.1
C and C++ also violate (2) in many ways. For example, C++ requires private member variables and functions to be declared in the class body (which will go into the header file for any public class), even though they are not part of the public API. Template functions also have to be defined in header files if users will instantiate them, even though the function definitions are implementation details. C and C++ both require a function to be defined in a header if you want it to be inlinable. For these reasons and others, C and C++ force a lot of implementation details into headers, which goes against my vision of what header files should be.
The Case for Header Files
The case for header files boils down to this: the split between interface and implementation is our primary tool in the struggle against software complexity. It is how we break software down into pieces that can be implemented, tested, and evolved separately from each other. A header file is a place to specify the interface contract between one component and the outside world.
The header file describes the user’s view of a software module, which is comprised of both the formal function declarations and the comments describing the semantics of those functions. Together these form the contract of the module’s API. If there is disagreement about whether a particular behavior is a bug or a feature, the header file is the contract we use to litigate what is promised vs what is not.
Without header files, where is this interface specified? It is sprinkled across a mound of implementation details. There is no way to focus specifically on the parts of the API that are public. It’s like going to a restaurant and being presented with a menu that has full recipes for each item, and trying to glean from each recipe what the dish will be like.
The public interface can be extracted from this jumble by a tool like a documentation generator, which filters out the non-public functions and methods and generates some HTML. Indeed, a tool like Javadoc or rustdoc is the closest we can get to header files in many modern languages, and this does allow us to view the public API as a unified thing.
But generated docs are not integrated into the software authoring, versioning, and review process. They aren’t source files, so you can’t easily diff, blame, or comment on changes to them during code review. You probably won’t see them in your IDE or in the GitHub source browser. Doc generators are useful, but they cannot offer a versioned record of the public API the way header files can.
Auto-Generated Headers?
One of the main objections to header files is that they violate the principle of don’t repeat yourself. A header file must be updated whenever the corresponding source file changes (if a public API was affected). This is busy work, which is tedious and a drag on developer productivity.
What if we take inspiration from doc generators and make a tool do the work for us? What if we tweaked a doc generator to spit out code instead of HTML?
Let’s take the following example in Rust:
// example.rs: a normal Rust source file.
struct Foo {
a: i32,
b: i32,
}
/// The Bar type.
#[repr(C)]
pub struct Bar {
a: i32,
pub b: i32,
}
impl Foo {
pub fn new() -> Foo { Foo { a: 0, b: 0 } }
}
impl Bar {
/// Constructs a new Bar.
pub fn new() -> Bar { Bar { a: 0, b: 0 } }
fn add(&mut self, v: i32) {
self.a += v;
self.b += v;
}
}
You could imagine the compiler generating the following header file which specifies the public API:
// example.api.rs: A header file describing the public API.
// The compiler has removed all non-public APIs and all implementation. It has
// kept the rustdoc comments, because those comments are part of the API
// contract.
/// The Bar type.
pub struct Bar {
pub b: i32,
}
impl Bar {
/// Constructs a new Bar.
pub fn new() -> Bar;
}
For projects that care about ABI stability, you could even imagine the compiler generating a separate “ABI Header” file:
// example.abi.rs: A header file describing the public ABI.
// The compiler has emitted ABI information about all public APIs. We only
// need to include ABI information that is not specified in the API itself;
// this includes:
// - struct members offsets.
// - enum constant numbers.
// - definitions of any function that is allowed to be inlined.
//
// Rust only supports a stable ABI for `#[repr(C)]`, so ABI information is
// only emitted for types that use the C ABI.
#[abi(size=8, align=4)]
pub struct Bar {
#[abi(offset=4)],
pub b: i32
}
This (hypothetical) compiler has done quite an interesting thing for us. It has extracted all aspects of our source file that are API- or ABI-impacting into a readable and parseable form. As we change the source file, we can monitor these generated header files to see if our changes affected the API or ABI.
Suppose we change Bar::a (a private member) from i32 to bool. Does it
change the public API? No, because Bar::a is private, so example.api.rs
will be unchanged.
Does changing Bar::a from i32 to bool change the public ABI? Again no,
because padding will cause Bar::b’s offset to remain 4. So this change
will not result in any diff to example.abi.rs.
But what if we changed Bar::a to i64? Then Bar::b’s offset will change to
8, which is an ABI break, and this will be reflected by a corresponding
change in example.abi.rs.
This is useful information for humans, but it could also be a signal to the
build system. How do we know if dependent modules need to be recompiled?
Only if our API or ABI changed, which we can detect by monitoring changes
to example.api.rs and example.abi.rs.2
We will want to generate these files as eagerly as possible, so we get early feedback. API headers should definitely be checked into source control, so that they are versioned and visible to code review. Checking in ABI headers will probably be overkill for projects that do not care about ABI stability.
Benefits
There are many practical examples of cases where header files help with software engineering. I will argue this case with some specific examples.
Deep Modules
In John Ousterhout’s book A Philosophy of Software Design, he argues that one of the most important design principles in software is to make modules deep, such that a relatively small interface hides a large amount of implementation.
He illustrates this point in the following diagram, which is taken from the book:
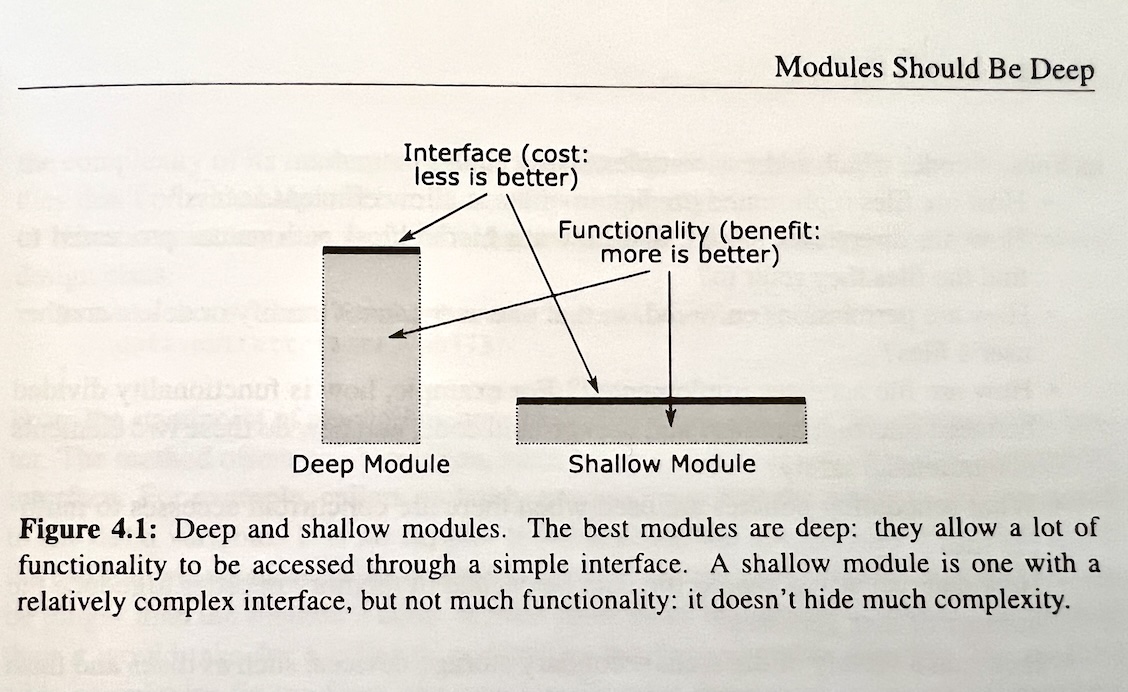
Over the years I have come to solidly agree with this principle. The best designs are ones where the ratio of interface size to implementation size is kept as low as possible. The motivation is to hide complexity, so that a user of your module does not have to see all of the implementation details.
How can we keep tabs on how deep our modules are? If we have some code open in an editor, or in a code review, how can we tell how well we are doing?
If we are using header files, the answer to this question is pretty simple: just compare the size of the header file to the size of the source file. The deepest modules will have very small header files – maybe only a single function! – and much larger source files. We should get a good feeling when our header files are small, and a sense of dread when they are large and sprawling. Big header files are a code smell.
For languages that do not use headers, it is much more difficult to eyeball how
deep a module is. A deep module would be one where the public keyword
appears only a few times in a file that is hundreds or thousands of lines long.
But this is not easy to measure visually, and it is not easy to spot in code
review.
Searching for the public keyword doesn’t even really answer the question,
because a public method could be a public API of a private type, in which
case it is not truly exported from the module. For example, consider the
following code in Java:
class Square {
private class Squarer {
private int[] arr;
// These are public methods, but on a private type, so not truly
// part of the module's public API!
public Squarer(int[] arr) { this.arr = arr }
public square() {
for (int i = 0; i < arr.length; i++) {
arr[i] = squareNumber(arr[i]);
}
}
}
// This is the only truly public API.
public static int squareArray(int[] arr) {
new Squarer(arr).square();
}
}
The public keyword shows up three times in this source file, but only one
of these is actually visible outside of this file. So it is actually quite
hard to gauge how deep a module is in most programming languages. With header
files, it is trivial.
Software Versioning
For people who maintain software libraries, one of the key questions we have to ask is whether a given change will break users or not. Breaking changes are intrusive, because they force users to change their code.
This principle is built into versioning schemes like SemVer, which requires that any breaking API change be accompanied by a major version bump.
How can we quickly evaluate whether a given change might be breaking or not? If we are using header files, we can look at whether a given change modifies a header file or not. If no header files are changing, it guarantees that we are not changing the API contract (the change could introduce a bug that violates the API contract, but that is a separate issue). Conversely, if header files are changing, there is a high likelihood that public APIs are being either added or changed.2
As an illustration, let’s play a little game. Here are the Git diffstats for four different changes in the Protobuf repository. Two of them are breaking changes and two are not. Can you guess which is which?
$ git diff --stat 63623a688c0f4329cfe4161bbaa2666f34c2be33^ 63623a688c0f4329cfe4161bbaa2666f34c2be33 .../main/java/com/google/protobuf/Descriptors.java | 10 +-------- .../com/google/protobuf/util/ProtoFileUtil.java | 21 +++++++++++++++++++ .../google/protobuf/util/ProtoFileUtilTest.java | 24 ++++++++++++++++++++++ 3 files changed, 46 insertions(+), 9 deletions(-) $ git diff --stat e3cc31a12eaddcfaaa5a27c272e240b6cbd985c8^ e3cc31a12eaddcfaaa5a27c272e240b6cbd985c8 .../com/google/protobuf/AbstractMessageLite.java | 10 +++++++-- .../com/google/protobuf/ProtobufArrayList.java | 26 ++++++++++++++++++---- 2 files changed, 30 insertions(+), 6 deletions(-) $ git diff --stat e2eb0a19aa95497c8979d71031edbbab721f5f0a^ e2eb0a19aa95497c8979d71031edbbab721f5f0a src/google/protobuf/util/json_util.h | 3 --- 1 file changed, 3 deletions(-) $ git diff --stat f549fc3ccc4ea096fcbc66f74c763880cd26e451^ f549fc3ccc4ea096fcbc66f74c763880cd26e451 src/google/protobuf/descriptor.cc | 14 +++++--------- 1 file changed, 5 insertions(+), 9 deletions(-)
C++ has an unfair advantage in this game. When a C++ change only touches .cc
files, we are guaranteed that the API contract is not changing, so we know that
change #4 does not break API or ABI. When a change
touches .java files, we get no hint about whether the change affects the API,
implementation, or both. It turns out that change #1 is API-breaking and change
#2 merely changes internal implementation details, but the Git diffstats offer
no clue about this.3
Rust has tools for checking for breaking changes: I found cargo-semver-checks, cargo-public-api, and rust-semverver. These tools can be set up to run in CI workflows, and will raise errors if a public API was added or changed without a corresponding version bump. A tool like this can arguably solve the problem, without any need for header files.
But there is a price to making the API checker a separate tool. It means that
people need to opt in by manually setting up the tool in their workflow, which
few projects actually do. A 2023 study found that 17.2% of Rust crates have
at least one semver
violation.
And this only counts the violations that cargo-semver-checks is able to
detect; the tool is known to be incomplete and will miss some issues.
The authors of the study argue that “This is a failure of tooling, not humans”, and I agree. It is not up to humans to be perfectly diligent about API breaks, it is up to the tooling to surface these issues as conveniently as possible. What better way to do this than to make interface definition a part of the language itself, as code that can be viewed in your editor and in version control?
If you are changing a public API, you want to get this feedback as early as possible. The ideal time to get that feedback is in your source code editor, the moment when you type the change. The second-best time is when you run the compiler. The third-best time is in CI. The fourth-best time is in code review. The fifth-best time is when you go to actually perform a release. The worst time is from a user, once you have broken their build. Early feedback is key, and header files provide early feedback by surfacing API/ABI changes as file diffs at the source code editing stage.
Header files also let you view API diffs and versions using a normal git
diff, rather than having to invoke a special tool. So it’s very cool that
tools like cargo-semver-checks exist, but I think header files could take
it to the next level by versioning the API declarations themselves.
Precompiled Libraries
Suppose you are shipping precompiled libraries (.a, .so, .dll, .dylib
etc). What can you ship along with the compiled library that will describe
the APIs that are contained in that library?
Header files have always been a natural fit for this, because they contain the API definition without any associated implementation. For example, let’s look at the Ubuntu package for zlib (filtering out examples and manpages):
$ dpkg -L zlib1g-dev | grep -v share
/.
/usr
/usr/include
/usr/include/zconf.h
/usr/include/zlib.h
/usr/lib
/usr/lib/aarch64-linux-gnu
/usr/lib/aarch64-linux-gnu/libz.a
/usr/lib/aarch64-linux-gnu/pkgconfig
/usr/lib/aarch64-linux-gnu/pkgconfig/zlib.pc
/usr/lib/aarch64-linux-gnu/libz.so
The header and the precompiled library are a natural pair: the header describes
the API, while the .a/.so implements it.
How does one distribute precompiled libraries in a language without headers? Looking at the few languages we opened the article with:
- Java: Compiled
.jarfiles do not contain a human-readable description of the interface. You have to go looking for Javadoc somewhere, and hope it matches the version of the library you have installed. - Rust: Rust does not have a stable ABI, and therefore does not support distributing precompiled libraries. For the C ABI, you would probably just distribute a C header file.
This is another use case for header files, which can represent an API/ABI without including any implementation.
Honorable Mentions
While no modern language has fully embraced header files, there are a few that deserve partial credit.
Python & Ruby: Interface Files
Python and Ruby have both evolved some static typing infrastructure that augments the native dynamic typing of the language. As part of this trend, both languages allow you to declare APIs in a separate file from the implementation.
In Python, these are .pyi files:
# Python uses .pyi files for static API declarations.
# These are called "stub files" and are standardized in PEP 484:
# https://peps.python.org/pep-0484/#stub-files
def square_list(ls: Sequence[int]): ...
In Ruby, these are .rbs files:
# Ruby uses .rbs files for static API declarations.
# These are known as type signatures, and are standardized in:
# https://github.com/ruby/rbs
def square_array(arr: Array[int])
This design ticks a lot of the boxes I’m arguing for. But what it lack is
completeness: there is no guarantee that all public APIs will be listed in
these files. An API can be called even if it is in the source file (.py or
.rb) only.
This means we do not get the guarantee we want, which is that changes affecting source files only are perfectly API-preserving.
Kotlin: expect/actual
Kotlin is aimed at cross-platform development, and it has a language feature designed to let you specify an API that will have different implementations on different platforms.
// Kotlin Common API can contain "expect" declarations, which soecify an API
// without providing any implementation.
expect fun squareArray(arr: Array<Int>)
fun squareNumber(x: Int): Int {
return x * x;
}
// Implementation for a given platform.
actual fun squareArray(arr: Array<Int>) {
for (i in arr.indices) {
arr[i] = squareNumber(arr[i])
}
}
This bears some similarity to my preferred solution. But this mechanism does
not attempt to separate interface from implementation for all APIs, only for
APIs that have different implementations on different platforms. APIs that
define a single implementation for all platforms do not use expect and
actual:
// Kotlin Common code can define function implementations without using
// `expect` or `actual`.
fun squareNumber(x: Int): Int {
return x * x;
}
fun squareArray(arr: Array<Int>) {
for (i in arr.indices) {
arr[i] = squareNumber(arr[i])
}
}
-
This is of course assuming that people actually adopt C++20 modules. I do not have much experience with modules myself, so I can’t guess how this will go. ↩
-
If we are tracking ABI, the same is also true of ABI stability: any commit that changes a
foo.abi.rsfile would imply an ABI break. ↩ ↩2 -
In reality, many non-breaking changes in C++ touch
.hfiles, due to the shortcomings of C++ headers I described earlier. But the ideal I am arguing for does not suffer this problem, since I argue that header files should only contain public APIs. ↩